Topic 1: Design of Experiments (实验设计)
核心概念
Controlled Experiments (对照实验)
- 定义: Variables that may influence the outcome are controlled
- 特点: 两个平行实验仅在是否施加treatment上有差异
- 目的: 分离treatment effect from confounding variables
Control Groups (对照组)
- Contemporaneous control groups: 对照组与实验组同时进行
- Historical control groups: 对照组早于实验组进行
Double-Blind Test 双盲检验
-
定义: 实验中受试者和实验操作者都不知道哪些受试者接受了实验处理,哪些接受了对照处理的实验设计方法
-
结构:
- 受试者不知道自己所在组别(盲法第一层)
- 实验操作者/数据收集者不知道受试者组别(盲法第二层)
- 只有独立的数据分析者在分析阶段才揭盲
-
对比:
- 单盲: 仅受试者不知道分组
- 双盲: 受试者和操作者都不知道分组
- 三盲: 增加数据分析者也不知道分组
-
特点:
- 消除安慰剂效应 (placebo effect)
- 消除实验者偏倚 (experimenter bias)
- 提高实验结果的客观性和可信度
- 是随机对照试验 (RCT) 的金标准
Simpson's Paradox (辛普森悖论)
-
定义: 在分组数据中,各组内部都呈现某种趋势,但合并数据后却呈现相反的趋势
-
数学表示:
- 分组内: 对所有组 成立
- 合并后:
-
经典案例:
- 加州大学伯克利分校录取案例(1973):
- 整体: 男性录取率高于女性
- 分专业: 几乎每个专业女性录取率都高于或等于男性
- 原因: 女性更多申请竞争激烈的专业
- 加州大学伯克利分校录取案例(1973):
-
特点:
- 由混杂变量(confounding variable)引起
- 样本量分布不均是关键因素
- 提醒我们不能只看汇总数据
- 需要进行分层分析(stratified analysis)
Confounding and Bias (混淆与偏倚)
Confounding (混淆)
- 一个变量的效应与另一个变量混合,导致解释上的困惑
- 例如:年龄、性别、社会经济地位等
Bias (偏倚) - 影响数据准确测量treatment effect的因素
1. Selection Bias (选择偏倚)
- 定义: Treatment group与control group不可比,两组差异会混淆treatment效应
- 例子: Portacaval Shunt 1966实验 - 更健康的患者被分配到treatment组
- 解决方案: Randomised Control Trial (RCT) - 随机对照试验
2. Observer Bias (观察者偏倚)
- 定义: 受试者或研究者可能下意识地报告更有利或不利的结果
- 解决方案:
- Placebo (安慰剂): 设计为中性且与真实treatment无法区分的假治疗
- Placebo effect: 受试者认为自己接受了治疗而产生的效应
- Randomised Controlled Double-blind trial (双盲随机对照试验):
- 受试者和研究者都不知道哪组是treatment组,哪组是control组
- 安慰剂应尽可能与真实treatment相似
- 需要第三方管理treatment和placebo的分配
3. Consent Bias (同意偏倚)
- 定义: 当受试者选择是否参与实验时产生
- 解决方案: Double-blind allocation,但需考虑伦理问题
Limitations (局限性)
- 使用信息不足的回顾性数据库
- 样本量不足
- 缺乏安慰剂对照和随机化(主要由于伦理原因)
- 结论: 虽然RCT更可取,但大多数情况下无法进行,因此进行观察性研究
Observational Studies (观察性研究)
- 当RCT不可行时的替代方案
- 研究者观察而不干预
- 更容易受到confounding和bias的影响
Ethics and Privacy (伦理与隐私)
- 数据收集、存储、交换、访问和报告需要透明
- 结果应该是不可识别的(匿名的)
- 年轻人如果理解目的和好处,通常愿意分享数据
Domain Knowledge (领域知识)
- 帮助理解数据的背景信息
- 信息应该是可信的、可靠的、可重复的
- Reproducible: 可以被第三方检查的数据报告
Topic 2: Summarising and Visualising Data (数据总结与可视化)
Graphical Summaries (图形总结)
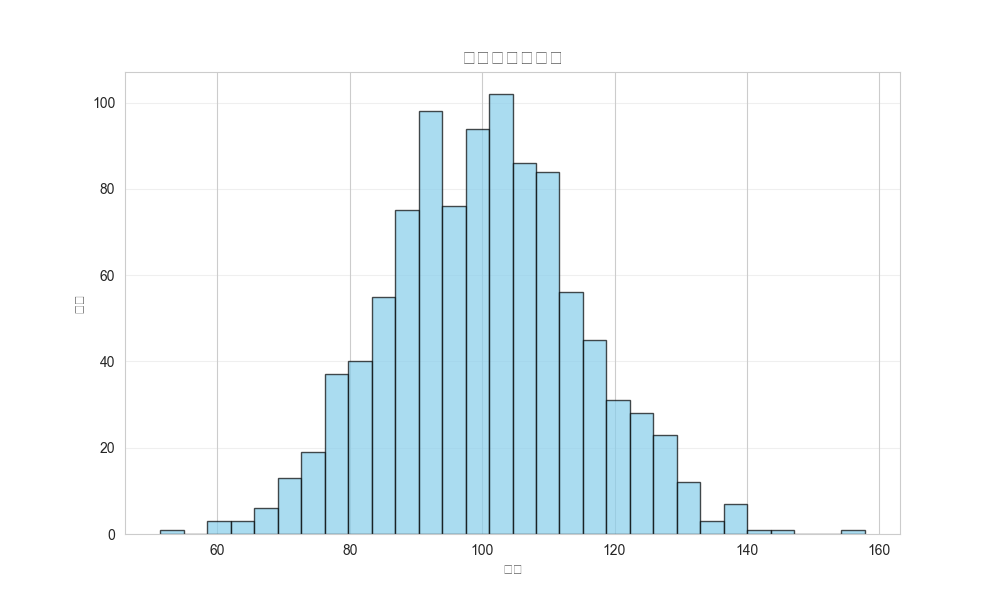
Histogram (直方图)
用途:
- 显示连续数据的频数分布
- 观察数据的集中趋势和离散程度
- 判断数据是否符合正态分布
适用场景:
- 考试成绩分布
- 身高、体重等生理指标分布
- 测量误差分析
图形解读:
- 柱子高度:该区间内的数据频数
- 柱子宽度:数据分组的区间大小
- 整体形状:对称表示正态,偏斜表示数据不均匀
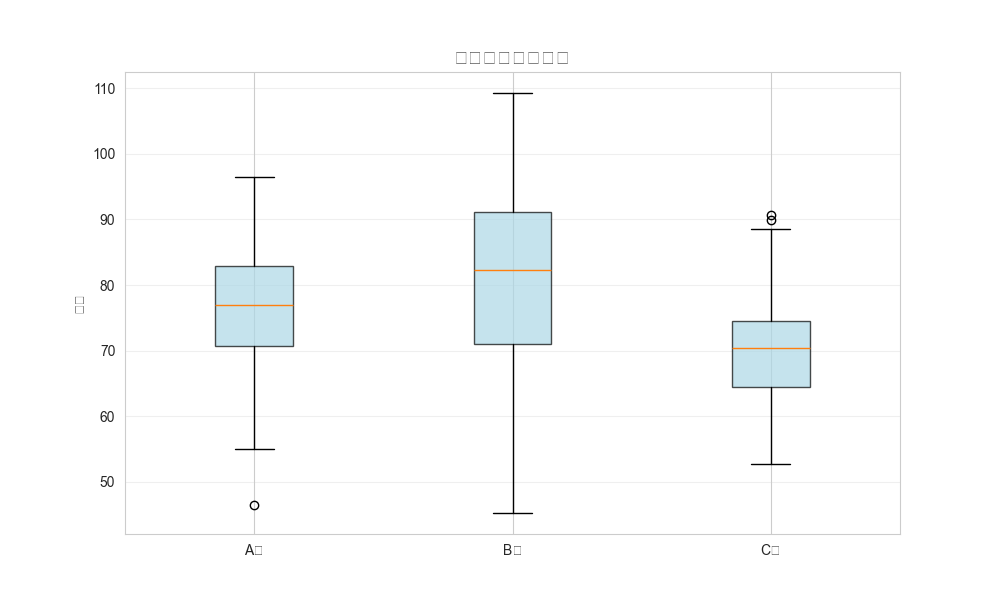
### Box Plot (箱线图)
用途:
- 显示数据的五数概括:minimum, Q1, median, Q3, maximum
- 识别outliers(异常值)
- 比较多组数据的分布
适用场景:
- 多个班级成绩对比
- 不同地区收入水平比较
- 实验组与对照组数据对比
图形解读:
- 箱体:Q1到Q3(包含50%的数据)
- 中线:中位数
- 须:1.5倍IQR范围内的最值
- 圆点:异常值
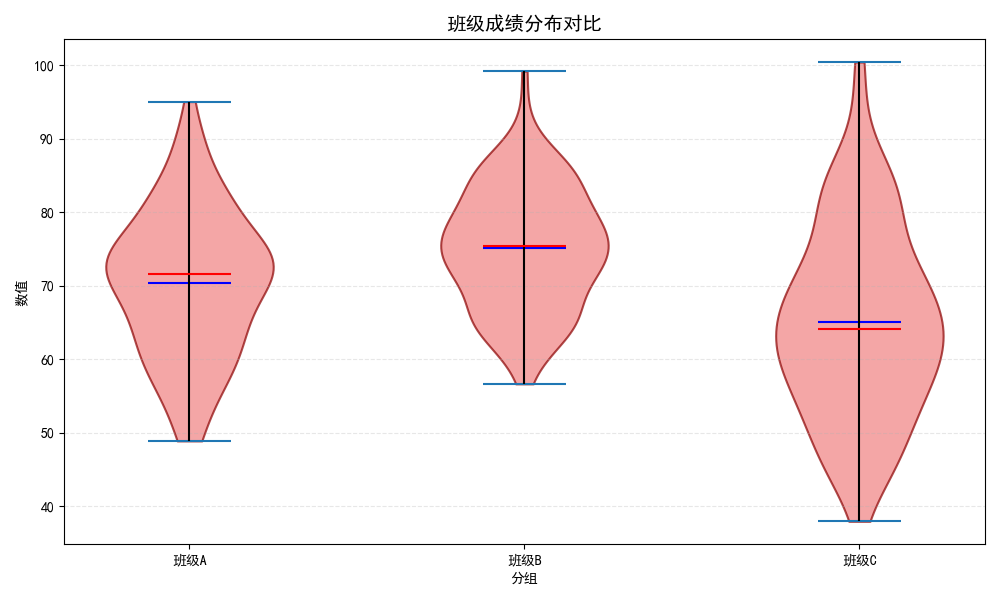
Violin Plot (小提琴图)
用途:
- 结合箱线图和密度图的优点
- 显示数据的完整分布形状
- 比较多组数据的分布差异
适用场景:
- 多组数据的详细分布对比
- 观察数据的多峰性
- 展示数据的对称性
图形解读:
- 宽度:该数值处的数据密度
- 中间白点:中位数
- 黑色粗线:四分位距
- 细线:数据范围
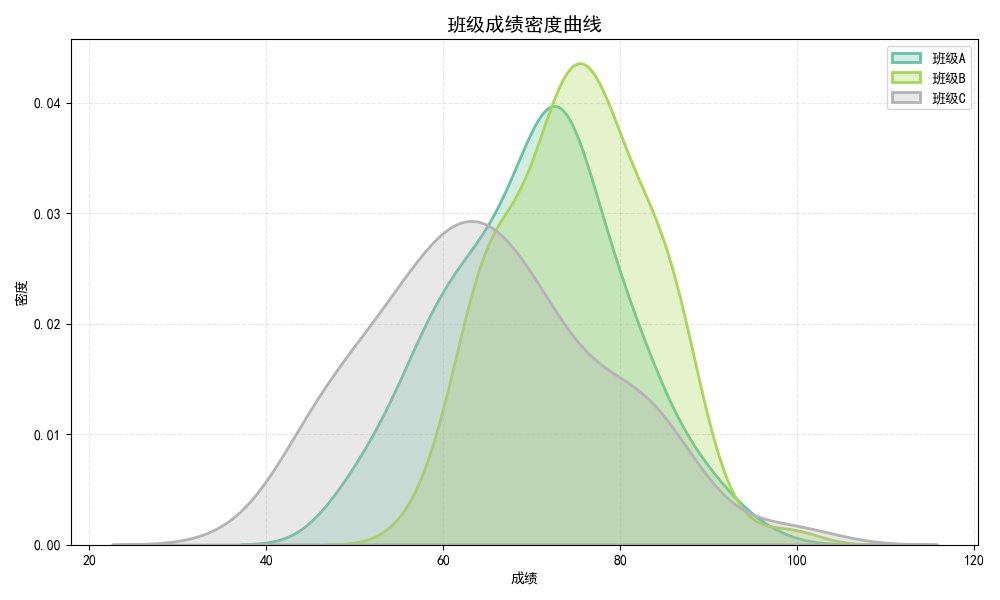
Density Plot (密度图/核密度估计图)
用途:
- 显示数据的概率密度分布
- 平滑的分布曲线(相比直方图)
- 观察数据的峰值和形状
适用场景:
- 连续变量的分布可视化
- 多组数据的分布对比
- 识别数据的偏态和峰度
图形解读:
- 曲线高度:该数值出现的相对概率
- 峰值:数据最集中的位置
- 曲线宽度:数据的离散程度
Scatter Plot (散点图)
用途:
- 显示两个连续变量之间的关系
- 观察数据的相关性和趋势
- 识别异常值和聚类
适用场景:
- 身高与体重的关系
- 学习时间与成绩的关系
- 广告投入与销售额的关系
图形解读:
- 点的分布:变量间的关系模式
- 正相关:从左下到右上
- 负相关:从左上到右下
- 无相关:随机分布
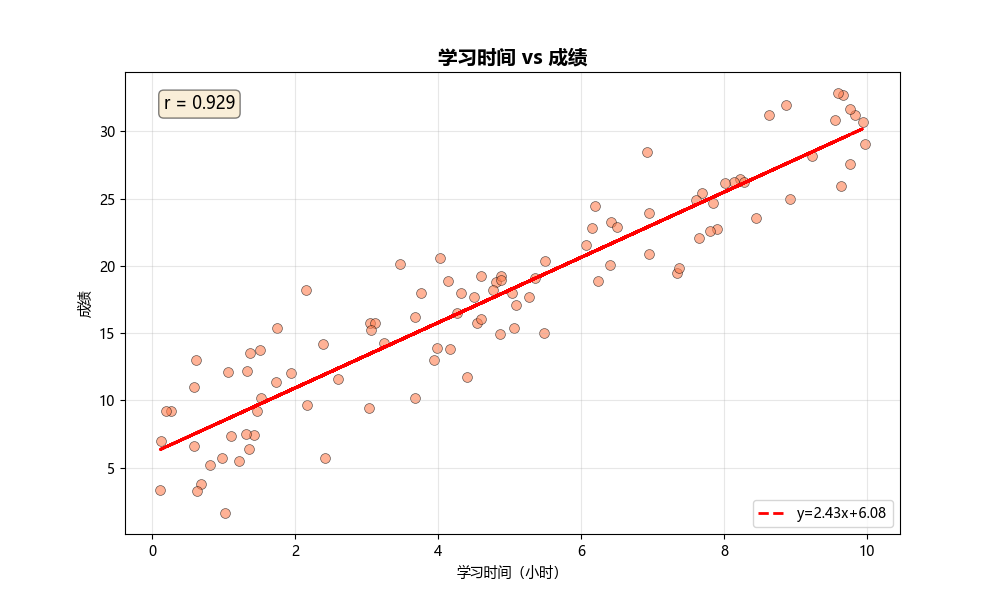
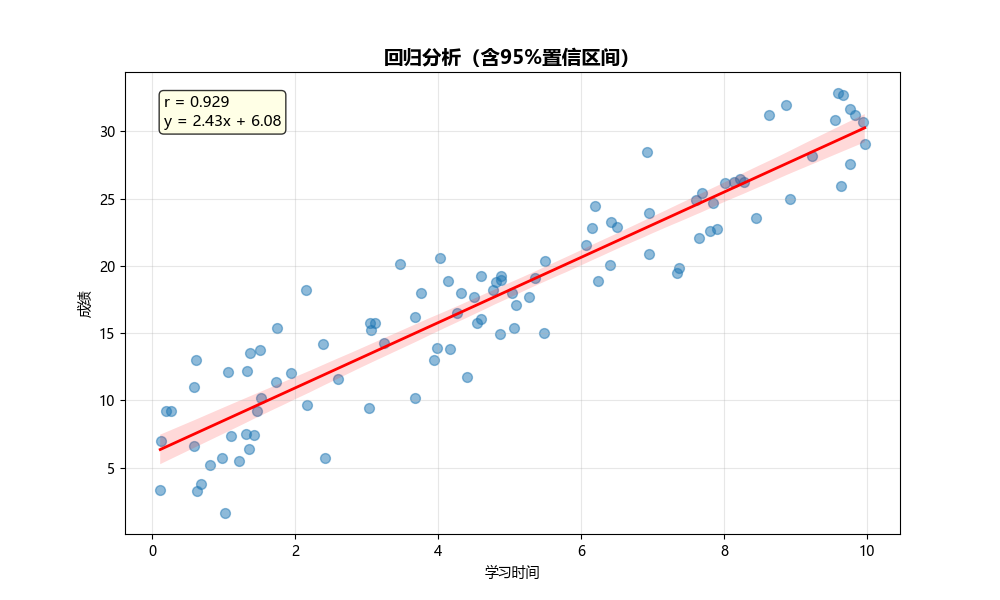
Regression Plot (回归图)
用途:
- 显示两变量的线性关系
- 展示回归线和置信区间
- 评估拟合优度
适用场景:
- 预测模型可视化
- 因果关系分析
- 趋势线展示
图形解读:
- 蓝色线:回归直线
- 阴影区域:95%置信区间
- 点的分散程度:拟合效果
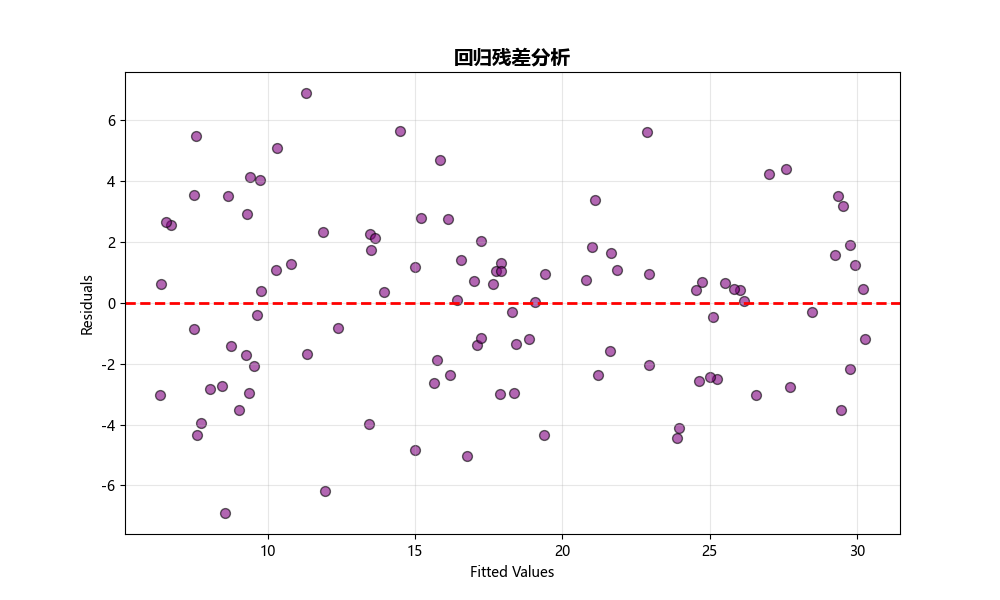
Residual Plot (残差图)
用途:
- 检验回归模型的假设
- 识别模型的系统性偏差
- 评估模型的适用性
适用场景:
- 回归分析诊断
- 模型验证
- 异方差检验
图形解读:
- 随机分布:模型假设成立
- 有规律模式:模型存在问题
- 喇叭形:存在异方差
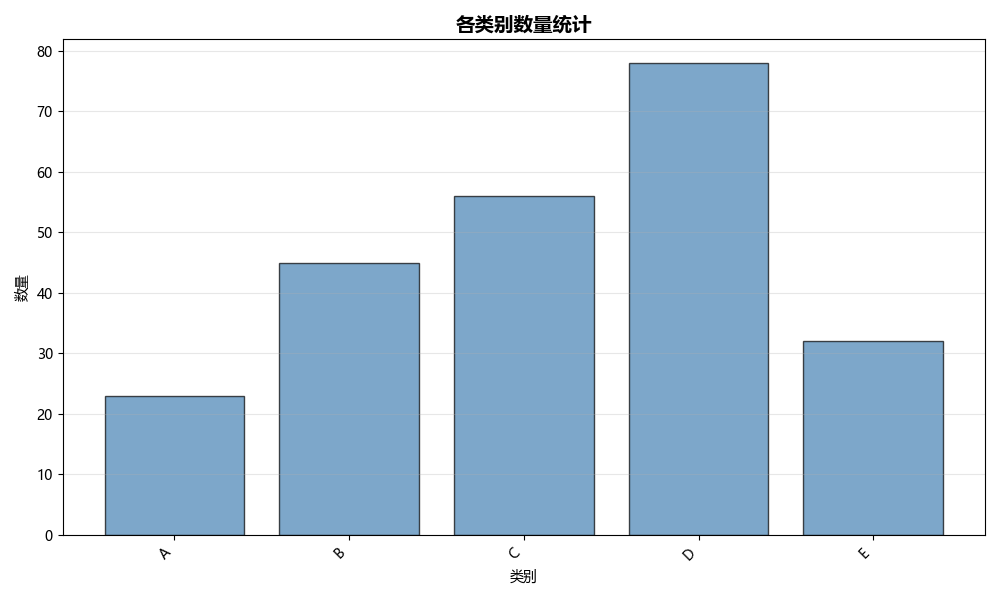
Bar Chart (条形图)
用途:
- 显示分类数据的数值大小
- 比较不同类别的数值
- 展示排名和对比
适用场景:
- 各部门销售额对比
- 不同产品的市场份额
- 各地区人口统计
图形解读:
- 柱子高度:该类别的数值大小
- 柱子颜色:可区分不同组别
- 排序:便于识别最大/最小值
Grouped Bar Chart (分组条形图)
用途:
- 比较多个类别在不同组别的数值
- 展示多维度的对比关系
- 时间序列的分类对比
适用场景:
- 多年度各季度销售对比
- 不同产品在各地区的销量
- 多组实验结果对比
图形解读:
- 同组柱子:同一类别的不同组别
- 柱子高度:数值大小
- 颜色:区分不同组别
Pie Chart (饼图)
用途:
- 显示各部分占总体的比例
- 展示构成关系
- 强调最大/最小份额
适用场景:
- 市场份额分布
- 预算分配比例
- 人口结构组成
图形解读:
- 扇形面积:该类别的占比
- 百分比标签:精确比例
- 颜色:区分不同类别
Line Plot (折线图)
用途:
- 显示数据随时间的变化趋势
- 比较多条时间序列
- 观察周期性和季节性
适用场景:
- 股票价格走势
- 月度销售趋势
- 温度变化曲线
图形解读:
- 线的斜率:变化速度
- 峰值和谷值:极值点
- 多条线对比:不同组别的趋势差异
Heatmap (热力图)
用途:
- 显示矩阵数据的数值大小
- 可视化相关系数矩阵
- 展示二维数据的模式
适用场景:
- 变量间相关性分析
- 时间-类别的交叉分析
- 地理热点分布
图形解读:
- 颜色深浅:数值大小
- 颜色聚类:相似模式
- 对角线:自相关(相关矩阵中)
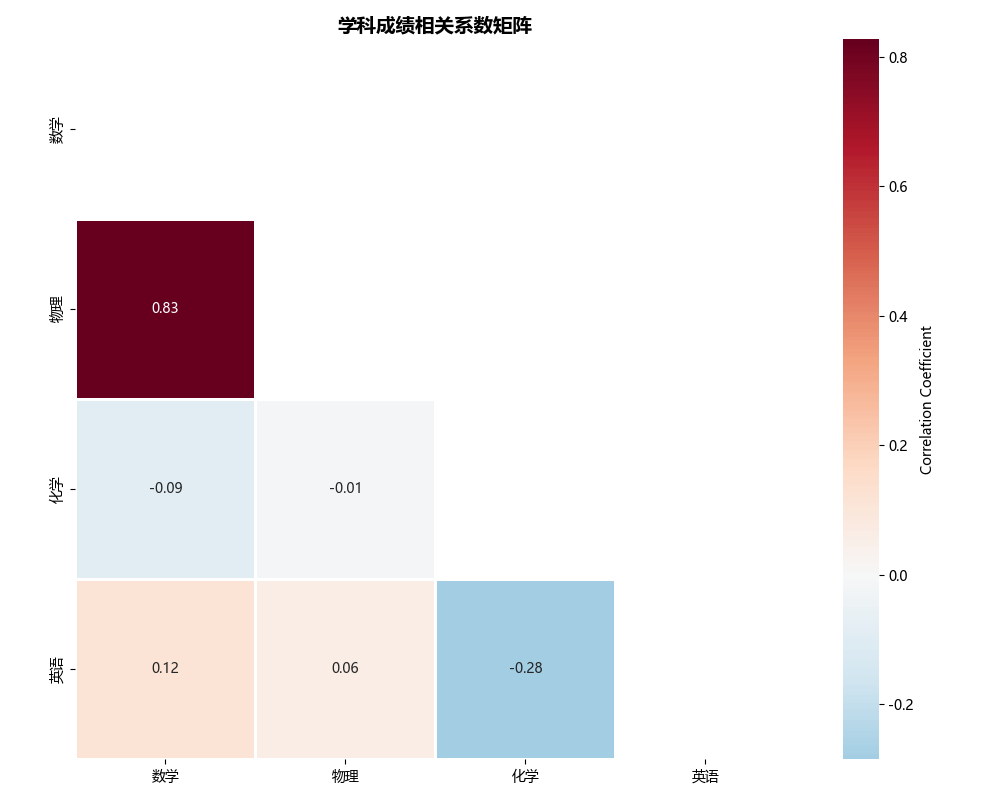
Correlation Matrix (相关系数矩阵图)
用途:
- 显示多个变量两两之间的相关系数
- 识别强相关变量
- 多重共线性诊断
适用场景:
- 特征选择
- 多元回归分析前的诊断
- 变量关系探索
图形解读:
- 数值:相关系数(-1到1)
- 颜色:正相关(红)、负相关(蓝)
- 对角线:自相关为1
Q-Q Plot (分位数-分位数图)
用途:
- 检验数据是否符合某种理论分布(通常是正态分布)
- 识别数据的偏态和厚尾
- 评估分布假设
适用场景:
- 正态性检验
- 回归分析前的假设检验
- 数据转换效果评估
图形解读:
- 点在直线上:符合理论分布
- 上端偏离:右偏或厚尾
- 下端偏离:左偏或薄尾
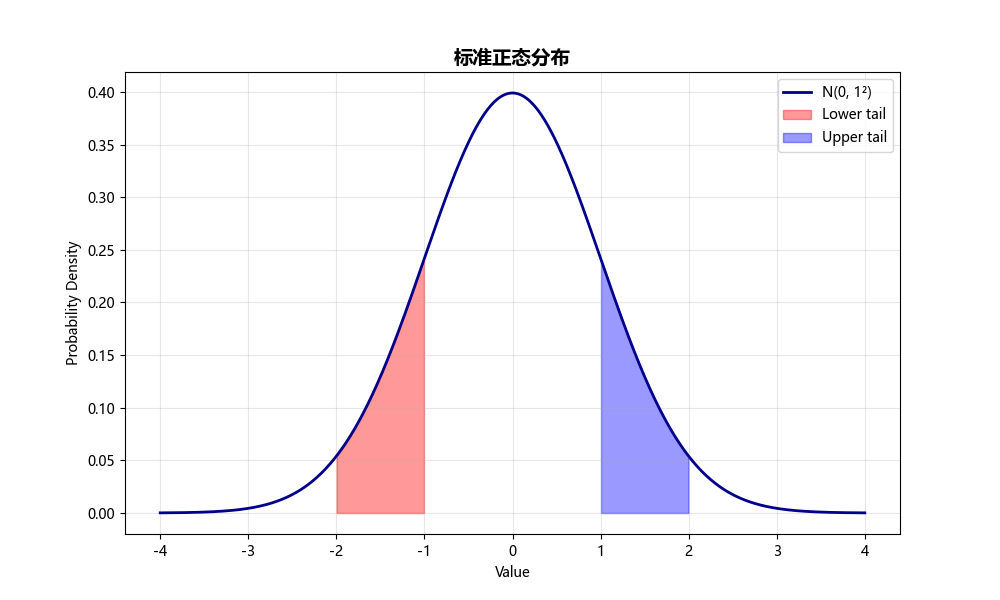
Normal Curve (正态分布曲线)
用途:
- 展示正态分布的概率密度
- 标注特定区域的概率
- 可视化假设检验的临界区域
适用场景:
- 概率计算可视化
- 置信区间展示
- 假设检验的拒绝域标注
图形解读:
- 曲线形状:钟形对称
- 阴影区域:特定概率范围
- 峰值:均值位置
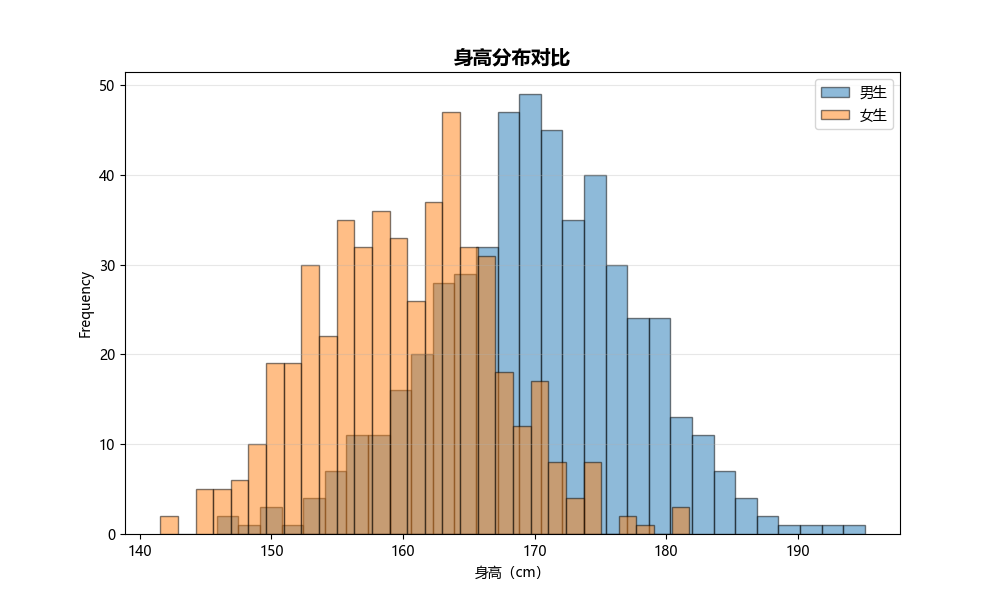
Overlapping Histograms (重叠直方图)
用途:
- 比较两组或多组数据的分布
- 观察分布的重叠程度
- 识别组间差异
适用场景:
- 男女生成绩分布对比
- 治疗前后数据对比
- 不同品种的测量值对比
图形解读:
- 重叠区域:两组数据的共同范围
- 透明度:便于观察重叠部分
- 峰值差异:中心位置的差异
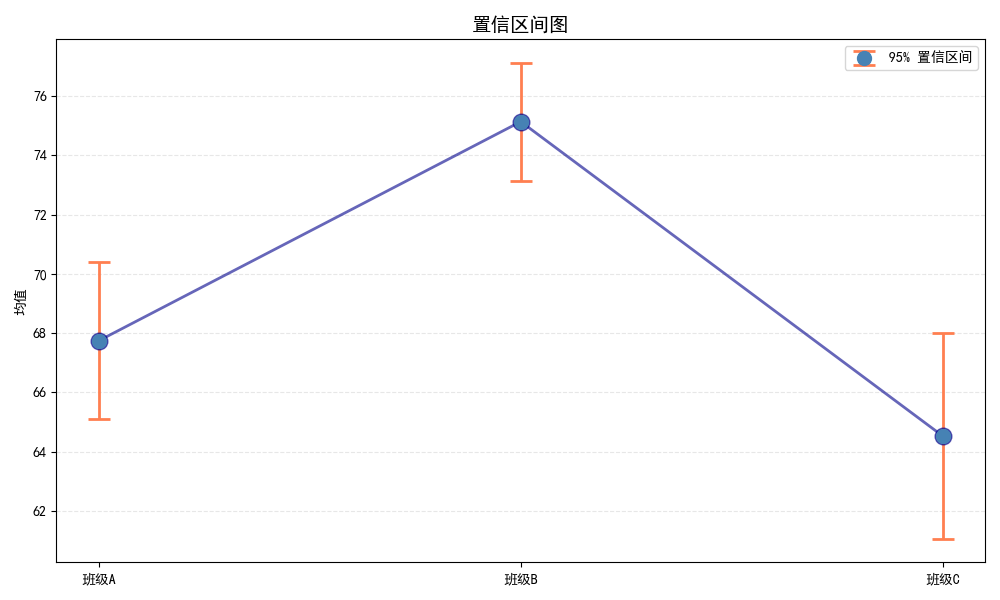
Confidence Interval Plot (置信区间图)
用途:
- 显示估计值及其不确定性
- 比较多组的均值和置信区间
- 评估组间差异的显著性
适用场景:
- 实验结果展示
- 调查数据的均值对比
- Meta分析的效应量展示
图形解读:
- 点:样本均值
- 误差线:置信区间范围
- 区间不重叠:可能存在显著差异
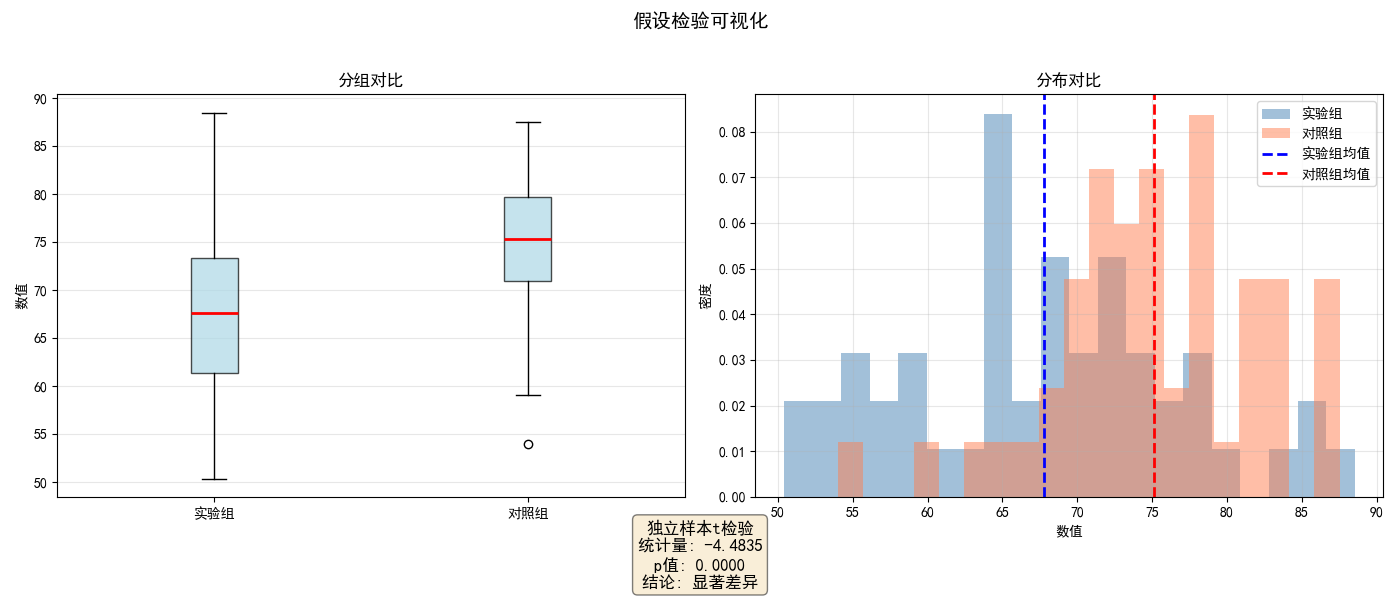
Hypothesis Test Visualization (假设检验可视化)
用途:
- 展示假设检验的原理
- 标注拒绝域和接受域
- 显示检验统计量的位置
适用场景:
- 教学演示
- 检验结果的直观展示
- 显著性水平的可视化
图形解读:
- 蓝色曲线:原假设下的分布
- 红色区域:拒绝域(α水平)
- 绿色线:观测值位置
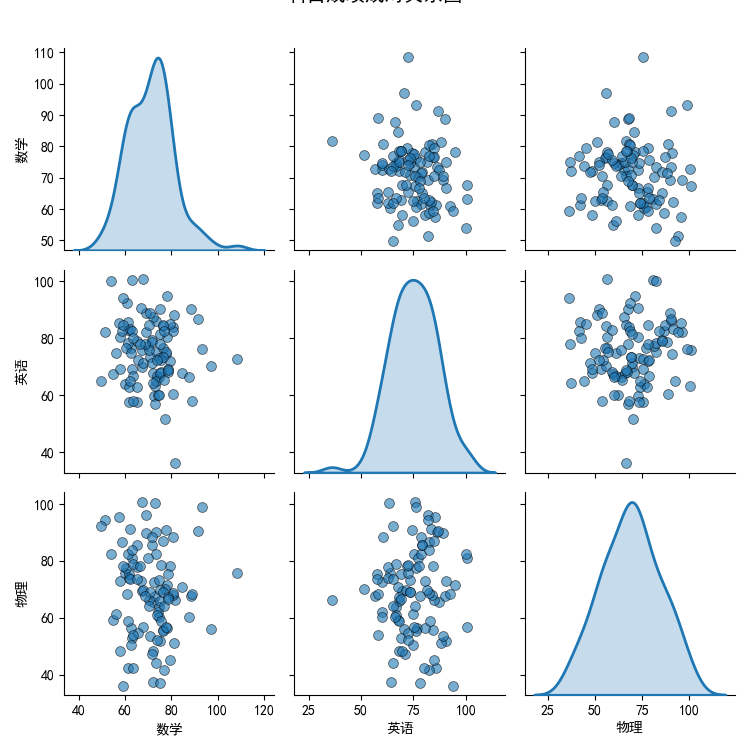
Pairplot (成对关系图)
用途:
- 显示多个变量两两之间的关系
- 对角线显示单变量分布
- 快速探索多变量数据
适用场景:
- 多元数据的初步探索
- 识别变量间的关系模式
- 特征工程前的分析
图形解读:
- 对角线:各变量的分布
- 非对角线:两变量的散点图
- 整体模式:变量间的关联结构
Parallel Coordinates (平行坐标图)
用途:
- 可视化高维数据
- 观察样本在多个维度上的模式
- 识别聚类和异常值
适用场景:
- 多指标综合评价
- 高维数据探索
- 分类问题的特征可视化
图形解读:
- 每条线:一个样本
- 线的走势:该样本在各维度的取值
- 线的聚集:相似样本群
Distribution Fitting (分布拟合图)
用途:
- 比较数据与多种理论分布的拟合效果
- 选择最佳拟合分布
- 评估分布假设
适用场景:
- 可靠性分析
- 风险评估
- 概率建模
图形解读:
- 灰色直方图:实际数据
- 彩色曲线:不同理论分布
- 拟合程度:曲线与直方图的贴合度
Stem Plot (茎叶图)
用途:
- 显示离散数据点
- 强调每个数据点的位置
- 适合小样本数据
适用场景:
- 离散时间序列
- 脉冲信号
- 小样本数据展示
图形解读:
- 竖线:数据点的位置和大小
- 基线:零值参考线
- 点:数据值
Strip Plot (带状图)
用途:
- 显示所有原始数据点
- 比较多组数据的分布
- 保留完整的数据信息
适用场景:
- 小样本数据可视化
- 展示数据的离散程度
- 结合箱线图使用
图形解读:
- 每个点:一个观测值
- 抖动:避免点重叠
- 点的密集度:数据集中程度
Swarm Plot (蜂群图)
用途:
- 显示所有数据点且不重叠
- 直观展示数据的分布形状
- 适合中小样本数据
适用场景:
- 精确展示每个数据点
- 小到中等样本量的分组对比
- 结合统计图使用
图形解读:
- 点的排列:形成分布的轮廓
- 宽度:该位置的数据密度
- 每个点可追溯:保留原始信息
ECDF Plot (经验累积分布函数图)
用途:
- 显示数据的累积概率分布
- 比较数据与理论分布
- 不依赖分组(无参数方法)
适用场景:
- 分布比较
- 百分位数查找
- 非参数统计分析
图形解读:
- Y轴:小于等于X值的数据比例
- 阶梯状:每个数据点处跳跃
- 最终到达1:100%的数据
Power Analysis Plot (统计功效分析图)
用途:
- 展示样本量、效应量与统计功效的关系
- 辅助实验设计中的样本量确定
- 评估检验的灵敏度
适用场景:
- 实验设计阶段
- 样本量计算
- 研究可行性评估
图形解读:
- X轴:效应量(Cohen's d)
- Y轴:统计功效(1-β)
- 不同曲线:不同样本量
- 0.8水平线:常用的功效标准
Measures of Centre (中心度量)
Mean (均值)
- 公式:
- R命令:
mean(data) - 特点:
- 受outliers影响大
- 是数据的"平衡点"
- 适用于对称分布
Median (中位数)
- 定义: 数据排序后的中间值
- 计算:
- 奇数个数据:中间位置的值
- 偶数个数据:中间两个值的平均
- R命令:
median(data) - 特点:
- Robust (稳健): 不受outliers影响
- 适用于偏态分布
- 对于房价等数据更有意义
Comparing Mean and Median (比较均值与中位数)
| 分布类型 | 关系 | 特征 |
|---|---|---|
| Symmetric (对称) | 均值等于中位数 | |
| Left-skewed (左偏) | 均值小于中位数 | |
| Right-skewed (右偏) | 均值大于中位数 |
Measures of Spread (离散度量)
Range (极差)
- 公式:
- R命令:
max(data) - min(data) - 简单但受极端值影响
Standard Deviation (标准差)
*Standard Deviation (标准差)
Population SD (总体标准差)
- R命令:
popsd(data)(需要multicon包)
Sample SD (样本标准差)
- R命令:
sd(data)
Root Mean Square (RMS)
- 步骤:
- Square the numbers (平方)
- Mean the result (求均值)
- Root the result (开方)
- 公式:
关系:
Variance (方差) = SD²
Interquartile Range (IQR, 四分位距)
- 公式:
- R命令:
IQR(data) - 特点: Robust,不受outliers影响
- 表示中间50%数据的范围
Standard Units (标准单位)
定义: 数据点距离均值多少个标准差
反向计算:
用途: 比较不同数据集中的数据点
The Empirical Rule (经验法则)
对于近似正态分布的数据:
- 68% 的数据在均值 ± 1 SD 范围内
- 95% 的数据在均值 ± 2 SDs 范围内
- 99.7% 的数据在均值 ± 3 SDs 范围内
Robustness (稳健性)
- Median和IQR是robust: 不受outliers影响
- Mean和SD不是robust: 受outliers影响大
- 对于偏态数据或有极端值的数据,使用median和IQR更合适
Topic 3: Reproducible Reports (可重复性报告)
Reproducibility in Data Science (数据科学中的可重复性)
为什么需要可重复性?
- 验证结果的准确性
- 检测人为错误
- 发现故意篡改的结果
- 促进科学透明度和协作
Forms of Reproducible Reports (可重复性报告的形式)
1. R Script (.R文件)
- 文本文件,保存R代码和注释(使用#)
- 协作者可以运行.R脚本,代码和结果显示在console中
- 优点: 简单直接
- 缺点: 结果不在脚本中,需要单独查看
2. R Markdown (.Rmd文件)
- 数据科学的创作框架
- 保存并执行代码,同时生成高质量报告供协作者查看和验证
- 组成部分:
- Chunks of text (用Markdown编写)
- Embedded code (如R, Python, SQL)
- LaTeX (数学公式)
- 输出格式: HTML, PDF, MS Word, Beamer, slides, books, dashboards, Shiny apps等
R Markdown实用技巧[[Markdown 技术文档]]
1. 代码注释
- 使用
#注释代码 - 确保理解代码
- 便于协作和项目交接
2. 自定义代码块输出
echo=F: 不显示代码eval=F: 不显示结果message=F: 不显示错误警告
3. 运行代码块
- Run result inline: 内联运行
- Run result in console: 在控制台运行
- 通常在console运行更好,因为后续代码块可能依赖前面的
4. 在文本中嵌入R代码
- 用于提供注释和动态内容
5. 添加超链接
- Markdown语法:
[链接文本](URL)
6. 添加图片
自定义:
<div align="center">
<img src="figure/image.jpg" height="25%">
</div>7. 添加视频
- 通过URL嵌入
8. 添加表格
- 使用Markdown表格语法
Topic 4: The Normal Distribution (正态分布)
Normal Curve Properties (正态曲线性质)
特征
- Bell-shaped (钟形): 对称的钟形曲线
- Mean = Median = Mode: 均值、中位数、众数相等
- 对称性: 关于均值对称
- 渐近性: 曲线两端无限接近但不触及x轴
- 面积: 曲线下总面积 = 1 (100%)
参数
- Mean (μ): 决定曲线的中心位置
- Standard Deviation (σ): 决定曲线的宽度/离散程度
- 记号:
Standard Normal Distribution (标准正态分布)
- Mean = 0, SD = 1
- 记号:
- 任何正态分布都可以转换为标准正态分布
标准化公式:
R中的正态分布函数
pnorm() - 计算概率(面积)
- 用途: 计算曲线下的面积(概率)
- 语法:
pnorm(x, mean, sd) - 默认:
pnorm(x)假设mean=0, sd=1 - 例子:
pnorm(1.96)→ 0.975 (左侧面积)pnorm(1.96, lower.tail=F)→ 0.025 (右侧面积)pnorm(275, 284.3, sqrt(5.52))→ 特定分布的概率
qnorm() - 计算分位数
- 用途: 给定概率,找对应的x值(百分位数)
- 语法:
qnorm(p, mean, sd) - 例子:
qnorm(0.6)→ 找60%分位数qnorm(0.2, 10, 4)→ 在N(10, 16)中找20%分位数
数学记号到R记号的转换
例子1: 计算 当
pnorm(275, 284.3, sqrt(5.52)) - pnorm(270, 284.3, sqrt(5.52))例子2: 计算 当
pnorm(1.2, 3, 2, lower.tail=F)注意: R中正态分布记号是 ,第二个参数是方差,所以需要用sqrt()
应用
Empirical Rule的正态分布验证
- 68%的数据在
- 95%的数据在
- 99.7%的数据在
正态近似
- 当数据近似正态分布时,可以用正态曲线估计概率
- 用于假设检验和置信区间
Topic 5: Linear Model (线性模型)
Bivariate Data (双变量数据)
定义
- 涉及一对变量 ,
- X: Independent variable (自变量/解释变量/预测变量/回归变量)
- Y: Dependent variable (因变量/响应变量)
Scatterplot (散点图)
- 在同一2D平面上绘制两个变量
- 形成点云
- 用于可视化两变量关系
Five Numerical Summaries of a Scatterplot (散点图的五个数值总结)
- Mean of x:
- SD of x:
- Mean of y:
- SD of y:
- Correlation coefficient:
Linear Association (线性关联)
描述
- Association: 点围绕一条线聚集的紧密程度
- Strong association: 紧密聚集 → 可以很好地预测
- Positive association: 一个变量增加,另一个也增加
- Negative association: 一个变量增加,另一个减少
Centre and Spread of the Cloud (点云的中心和离散)
| 特征 | 度量 |
|---|---|
| Centre (中心) | Point of averages: |
| Horizontal spread (水平离散) | - 大多数点在 范围内 |
| Vertical spread (垂直离散) | - 大多数点在 范围内 |
Correlation Coefficient (相关系数)
定义
- 符号:
- 度量点围绕直线聚集的程度
- 同时指示线性关联的符号和强度
性质
- Pure number (无单位): 没有度量单位
- 范围:
- : 所有点在一条直线上(完美相关)
- : 点不围绕直线聚集(无线性关联)
- Symmetric (对称): 交换x和y不影响r
- Shift and scale invariant (平移和尺度不变): 不受单位变化影响
解释
- : 点云向上倾斜(正相关)
- : 点云向下倾斜(负相关)
- 接近1: 点更紧密地聚集在直线周围
- 接近0: 点更分散
计算
Population correlation coefficient (总体相关系数):
手工计算步骤:
- 计算x和y的standard units
- 将对应的standard units相乘
- 求乘积的均值
R命令:
cor(x, y) # 样本相关系数Regression Line (回归线)
定义
- 通过点云的"最佳拟合"直线
- 用于预测y基于x
方程
其中:
- : 预测的y值
- : Intercept (截距)
- : Slope (斜率)
斜率和截距的计算
Slope (斜率):
Intercept (截距):
R中拟合回归线
lm(y ~ x) # 线性模型
# 输出: Coefficients: (Intercept) a x b回归线的性质
- 通过点 : 回归线总是通过均值点
- 最小二乘法: 使残差平方和最小
- 预测方向: 用x预测y,而不是y预测x(不对称)
Residuals (残差)
定义
- Residual: 实际值与预测值的差异
性质
- 残差和为0:
- 正残差: 实际值高于预测值(点在线上方)
- 负残差: 实际值低于预测值(点在线下方)
Residual Plot (残差图)
- X轴: 预测值 或自变量
- Y轴: 残差
- 用途: 检查模型假设是否满足
RMS Error (均方根误差)
定义
- 度量预测的典型误差大小
- 残差的RMS
公式
解释
- : Coefficient of determination (决定系数)
- 表示x解释了y变异的比例
- 意味着x解释了64%的y变异
- : 未被解释的变异比例
- RMS error越小: 预测越准确
Homoscedasticity vs Heteroscedasticity (同方差性 vs 异方差性)
Homoscedasticity (同方差性)
- 定义: 残差的离散程度在所有x值上保持一致
- 残差图特征: 残差均匀分布在0周围,宽度恒定
- 假设: 线性回归的理想条件
Heteroscedasticity (异方差性)
- 定义: 残差的离散程度随x变化
- 残差图特征: 残差的宽度呈扇形或其他模式
- 问题: 违反线性回归假设,预测可靠性降低
- 解决方案: 数据转换或使用其他模型
Regression Fallacy (回归谬误)
定义
- 当两个变量不完全相关时,极端值倾向于向均值回归
- 误将自然回归现象解释为因果关系
例子
- 父母身高极高的孩子,身高通常比父母矮(但仍高于平均)
- 第一次考试成绩极差的学生,第二次通常会提高(但可能仍低于平均)
避免方法
- 理解相关不等于因果
- 考虑回归效应
- 使用对照组
Multiple Regression (多元回归)
定义
- 使用多个自变量预测一个因变量
R中的多元回归
lm(y ~ x1 + x2 + x3)解释
- : 在其他变量保持不变时,增加1单位对y的影响
- Adjusted : 考虑变量数量的决定系数
注意事项
- Multicollinearity (多重共线性): 自变量之间高度相关
- Overfitting (过拟合): 变量过多导致模型过于复杂
Transformations (数据转换)
为什么需要转换?
- 线性化非线性关系
- 稳定方差(处理异方差性)
- 使数据更接近正态分布
常见转换
1. Log Transformation (对数转换)
- 用途: 处理右偏数据,指数关系
- 公式: 或
- 例子: 收入、人口、房价
2. Square Root Transformation (平方根转换)
- 用途: 中度右偏数据
- 公式:
3. Reciprocal Transformation (倒数转换)
- 用途: 严重右偏数据
- 公式:
4. Power Transformation (幂转换)
- 用途: 各种非线性关系
- 公式: (p可以是任意实数)
转换后的回归
Log-Log Model (双对数模型):
- 解释: x增加1%,y增加b%
Semi-Log Model (半对数模型):
- 解释: x增加1单位,y增加 %
R中的转换
lm(log(y) ~ log(x)) # 双对数
lm(log(y) ~ x) # 半对数
lm(sqrt(y) ~ x) # 平方根转换Topic 6: Probability (概率)
Basic Probability (基本概率)
定义
- Probability (概率): 事件发生的可能性,介于0和1之间
- Sample space (样本空间): 所有可能结果的集合,记为S
- Event (事件): 样本空间的子集
概率的性质
- (某个结果必然发生)
- (不可能事件)
Probability Rules (概率规则)
1. Complement Rule (补集规则)
- : A的补集(A不发生)
2. Addition Rule (加法规则)
一般形式:
互斥事件 (Mutually exclusive):
- 如果 ,则:
3. Multiplication Rule (乘法规则)
一般形式:
独立事件 (Independent events):
- 如果A和B独立,则:
4. Conditional Probability (条件概率)
- 读作: "给定B发生时A发生的概率"
Independence (独立性)
定义
- 两个事件A和B独立,当且仅当: 或等价地:
检验独立性
- 如果 ,则A和B独立
- 如果 ,则A和B不独立(相依)
注意
- 独立 ≠ 互斥
- 互斥事件通常是相依的(除非其中一个概率为0)
Box Model (箱模型)
定义
- 概率问题的可视化工具
- 箱子里装有不同颜色或标记的票
- 从箱子中抽取票来模拟随机过程
组成部分
- Tickets (票): 代表可能的结果
- Box (箱子): 包含所有票
- Draw (抽取): 随机选择票的过程
抽取方式
With Replacement (有放回抽样)
- 每次抽取后将票放回箱子
- 每次抽取独立
- 概率保持不变
Without Replacement (无放回抽样)
- 抽取后不放回
- 抽取不独立
- 概率随抽取而变化
例子
箱子: [1, 1, 1, 0, 0] (3个1,2个0)
- 抽到1的概率:
- 抽到0的概率:
Law of Large Numbers (大数定律)
定义
- 当重复次数增加时,观察到的频率会收敛到理论概率
- 样本均值收敛到总体均值
数学表述
应用
- 解释为什么赌场长期总是赢
- 保险公司如何定价
- 民意调查的理论基础
注意
- Gambler's Fallacy (赌徒谬误): 认为过去的结果会影响未来独立事件的结果
- 例如: 连续抛5次正面后,认为下次更可能是反面(错误!)
Expected Value (期望值)
定义
- 随机变量的长期平均值
- 符号: 或
计算公式
离散随机变量:
箱模型:
性质
- 线性性:
- 加法性:
- 多次抽取:
例子
箱子: [1, 3, 5]
抛硬币: [0, 1] (0=反面, 1=正面)
Standard Error (标准误)
定义
- 度量随机变量的变异性
- 符号:
计算公式
单次抽取的SD:
有放回抽样n次的SE:
无放回抽样的SE:
- N: 箱子中票的总数
- n: 抽取次数
- : Correction factor (修正因子)
性质
- (SE与样本量的平方根成正比)
- 要使SE减半,需要样本量增加4倍
应用
- 估计抽样误差
- 构建置信区间
- 假设检验
Sum of Draws (抽取之和)
期望值
标准误
正态近似
- 当n足够大时,抽取之和近似服从正态分布:
例子
箱子: [0, 1] (各50%),抽取100次
- Sum ~ N(50, 25)
Topic 7: Sampling (抽样)
Population vs Sample (总体 vs 样本)
定义
- Population (总体): 我们想要了解的完整群体
- 参数: (均值), (标准差), (比例)
- Sample (样本): 从总体中选取的子集
- 统计量: (样本均值), (样本标准差), (样本比例)
为什么抽样?
- 总体太大,无法全部调查(人口普查除外)
- 节省时间和成本
- 有时调查是破坏性的(如产品测试)
Sampling Methods (抽样方法)
1. Simple Random Sampling (SRS, 简单随机抽样)
- 定义: 总体中每个个体被选中的概率相等
- 方法:
- 给总体中每个个体编号
- 使用随机数生成器选择
- 优点: 无偏,理论基础扎实
- 缺点: 需要完整的抽样框架,可能成本高
2. Stratified Sampling (分层抽样)
- 定义: 将总体分为同质的层(strata),然后从每层中随机抽样
- 步骤:
- 将总体分为互不重叠的层
- 从每层中进行SRS
- 合并样本
- 优点:
- 确保每个子群体都被代表
- 通常比SRS更精确
- 例子: 按年龄、性别、地区分层
3. Cluster Sampling (整群抽样)
- 定义: 将总体分为群(clusters),随机选择一些群,调查选中群中的所有个体
- 步骤:
- 将总体分为群
- 随机选择一些群
- 调查选中群中的所有成员
- 优点: 成本低,便于实施
- 缺点: 精度通常低于SRS
- 例子: 学校调查(随机选择学校,调查选中学校的所有学生)
4. Systematic Sampling (系统抽样)
- 定义: 每隔k个个体选择一个
- 步骤:
- 计算 (N=总体大小, n=样本大小)
- 随机选择1到k之间的起始点
- 每隔k个选择一个
- 优点: 简单易行
- 缺点: 如果总体有周期性模式,可能产生偏差
5. Convenience Sampling (便利抽样)
- 定义: 选择容易获得的个体
- 问题: 通常有偏,不能推广到总体
- 例子: 街头调查、网络调查
Bias in Sampling (抽样偏倚)
定义
- Bias (偏倚): 系统性误差,导致样本统计量系统性地偏离总体参数
类型
1. Selection Bias (选择偏倚)
- 某些群体被系统性地排除或过度代表
- 例子:
- 电话调查排除了没有电话的人
- 网络调查排除了不上网的人
2. Non-response Bias (无应答偏倚)
- 被选中的人拒绝参与或无法联系
- 问题: 应答者可能与非应答者系统性不同
- 例子:
- 忙碌的人更可能不回应
- 对主题不感兴趣的人不回应
3. Voluntary Response Bias (自愿应答偏倚)
- 人们自己选择是否参与
- 问题: 有强烈意见的人更可能参与
- 例子:
- 网络投票
- 电话热线调查
4. Undercoverage (覆盖不足)
- 抽样框架不包括总体的某些部分
- 例子: 使用电话簿作为抽样框架(遗漏无电话或未登记的人)
Sampling Distribution (抽样分布)
定义
- 样本统计量(如 )的概率分布
- 如果重复抽样多次,每次计算统计量,这些统计量的分布
样本均值的抽样分布
期望值:
- 样本均值是总体均值的无偏估计
标准误:
- 有放回抽样或总体无限大
有限总体修正:
- N: 总体大小
- n: 样本大小
- 当 时,修正因子可忽略
Central Limit Theorem (CLT, 中心极限定理)
陈述:
- 当样本量n足够大时,样本均值 的抽样分布近似正态分布,无论总体分布如何
条件:
- 样本量足够大(通常 )
- 样本独立
意义:
- 即使总体不是正态分布,样本均值也近似正态
- 为推断统计提供理论基础
Confidence Intervals (置信区间)
定义
- 估计总体参数的区间
- 以一定的置信水平(如95%)包含真实参数
总体均值的置信区间
公式 (σ已知):
公式 (σ未知):
其中:
- : 标准正态分布的临界值
- 95% CI:
- 90% CI:
- 99% CI:
- : t分布的临界值(自由度 = n-1)
- : 样本标准差
解释
- 正确: "我们有95%的信心,真实的总体均值在这个区间内"
- 正确: "如果重复抽样多次,95%的置信区间会包含真实均值"
- 错误: "真实均值有95%的概率在这个区间内"(参数是固定的,不是随机的)
影响因素
- 样本量n: n越大,区间越窄
- 置信水平: 置信水平越高,区间越宽
- 总体标准差σ: σ越大,区间越宽
R中计算置信区间
# 使用t.test
t.test(data)$conf.int
# 手工计算
mean(data) + c(-1, 1) * qt(0.975, df=length(data)-1) * sd(data)/sqrt(length(data))Sample Size Determination (样本量确定)
公式
要达到误差范围E(margin of error),所需样本量:
例子
要估计均值,误差范围±2,σ=10,95%置信水平:
Topic 8: Bootstrap (自助法)
Bootstrap Method (自助法)
定义
- 一种重抽样方法(resampling method)
- 从原始样本中有放回地重复抽样,生成多个bootstrap样本
- 用于估计统计量的抽样分布和构建置信区间
为什么需要Bootstrap?
- 不知道总体分布
- 无法用数学公式计算标准误
- 样本量有限,无法重复抽样
- 对复杂统计量(如中位数、相关系数)构建置信区间
Bootstrap Process (Bootstrap过程)
步骤
- 原始样本: 从总体中抽取大小为n的样本
- Bootstrap重抽样: 从原始样本中有放回地抽取n个观测,形成一个bootstrap样本
- 计算统计量: 对每个bootstrap样本计算感兴趣的统计量(如均值、中位数)
- 重复: 重复步骤2-3多次(通常B=1000或10000次)
- Bootstrap分布: 所有bootstrap统计量形成bootstrap分布
关键特征
- 有放回抽样: 每次抽样后放回,同一观测可能被多次选中
- 样本量相同: 每个bootstrap样本的大小与原始样本相同
- 重复次数: 通常B ≥ 1000
Bootstrap Distribution (Bootstrap分布)
定义
- 所有bootstrap统计量的分布
- 近似真实的抽样分布
性质
- 中心: Bootstrap分布的中心接近原始样本统计量
- 离散程度: Bootstrap分布的标准差估计真实的标准误
- 形状: 反映统计量的抽样分布形状
Bootstrap Standard Error (Bootstrap标准误)
定义: Bootstrap统计量的标准差
计算:
R中计算:
# 假设boot_means是所有bootstrap样本均值的向量
SE_boot <- sd(boot_means)Bootstrap Confidence Intervals (Bootstrap置信区间)
方法1: Percentile Method (百分位数法)
最常用的方法
95% CI:
- 下限: Bootstrap分布的2.5百分位数
- 上限: Bootstrap分布的97.5百分位数
R中计算:
quantile(boot_stats, c(0.025, 0.975))优点:
- 简单直观
- 不假设分布形状
- 适用于任何统计量
例子: 如果有10000个bootstrap均值,排序后:
- 下限 = 第250个值
- 上限 = 第9750个值
方法2: Standard Error Method (标准误法)
公式:
95% CI:
假设: 统计量近似正态分布
方法3: Basic Bootstrap Method (基本Bootstrap法)
公式:
不常用
Bootstrap in R (R中的Bootstrap)
手工实现
# 原始样本
data <- c(23, 45, 67, 34, 56, 78, 90, 12)
n <- length(data)
B <- 10000 # bootstrap重复次数
# 存储bootstrap统计量
boot_means <- numeric(B)
# Bootstrap循环
for(i in 1:B) {
# 有放回抽样
boot_sample <- sample(data, size=n, replace=TRUE)
# 计算统计量
boot_means[i] <- mean(boot_sample)
}
# Bootstrap标准误
SE_boot <- sd(boot_means)
# 95% 置信区间(百分位数法)
CI <- quantile(boot_means, c(0.025, 0.975))使用boot包
library(boot)
# 定义统计量函数
mean_func <- function(data, indices) {
return(mean(data[indices]))
}
# 执行bootstrap
boot_result <- boot(data, mean_func, R=10000)
# 查看结果
boot_result
# 计算置信区间
boot.ci(boot_result, type="perc") # 百分位数法Bootstrap的假设和限制
假设
- 原始样本代表总体: 样本应该是总体的良好代表
- 独立性: 观测值相互独立
- 样本量足够: 通常n ≥ 30
优点
- 分布自由: 不需要假设总体分布
- 通用性: 适用于各种统计量
- 简单: 概念简单,易于实现
- 灵活: 可以处理复杂的统计问题
缺点
- 计算密集: 需要大量重复计算
- 依赖原始样本: 如果原始样本有偏,bootstrap结果也有偏
- 小样本问题: 样本量很小时效果不佳
- 极端值: 对于估计极端分位数(如最大值、最小值)效果不好
Bootstrap vs 传统方法
| 特征 | Bootstrap | 传统方法 |
|---|---|---|
| 分布假设 | 不需要 | 通常需要正态性 |
| 适用统计量 | 任何统计量 | 主要是均值、比例 |
| 计算 | 计算密集 | 公式简单 |
| 样本量要求 | 中等到大 | 可以较小(如果满足假设) |
| 理论基础 | 重抽样理论 | 概率论 |
应用场景
适合使用Bootstrap的情况
- 估计中位数的置信区间
- 估计相关系数的置信区间
- 估计回归系数的置信区间
- 复杂统计量(如比率、差异)
- 不知道抽样分布的统计量
例子:中位数的Bootstrap CI
data <- c(12, 15, 18, 20, 22, 25, 30, 35, 100) # 有极端值
B <- 10000
boot_medians <- numeric(B)
for(i in 1:B) {
boot_sample <- sample(data, size=length(data), replace=TRUE)
boot_medians[i] <- median(boot_sample)
}
# 95% CI
quantile(boot_medians, c(0.025, 0.975))Topic 9: Tests for Proportions (比例检验)
Hypothesis Testing Framework (假设检验框架)
基本概念
Hypothesis (假设):
- 关于总体参数的陈述
Null Hypothesis (原假设, H₀):
- 默认假设,通常表示"无效应"或"无差异"
- 我们试图寻找证据来反对它
- 例如:
Alternative Hypothesis (备择假设, H₁或Hₐ):
- 研究假设,我们想要证明的
- 例如: (双侧)
- 或: (单侧)
假设检验的逻辑
- 假设H₀为真
- 计算在H₀为真的情况下,观察到当前数据(或更极端)的概率
- 如果这个概率很小,拒绝H₀
- 如果这个概率不小,不拒绝H₀(注意:不是"接受"H₀)
Test Statistic (检验统计量)
定义
- 从样本数据计算的值,用于检验假设
- 度量样本统计量与假设参数值的差异
Z-statistic for Proportions (比例的Z统计量)
公式:
其中:
- : 样本比例
- : 原假设中的比例
- : 标准误(在H₀下)
例子
- 样本: n=100, 成功60次,
P-value (P值)
定义
- 在原假设为真的条件下,观察到当前样本统计量(或更极端)的概率
- 度量数据与H₀的不一致程度
解释
- P值小: 数据与H₀不一致,有证据反对H₀
- P值大: 数据与H₀一致,没有足够证据反对H₀
计算(双侧检验)
步骤:
- 计算Z统计量
- P-value =
R中计算:
# 双侧
p_value <- 2 * pnorm(abs(z_obs), lower.tail=FALSE)
# 右侧(H₁: p > p₀)
p_value <- pnorm(z_obs, lower.tail=FALSE)
# 左侧(H₁: p < p₀)
p_value <- pnorm(z_obs)例子
- P-value =
Significance Level (显著性水平)
定义
- 符号:
- 拒绝H₀的阈值
- 常用值: 0.05, 0.01, 0.10
决策规则
- 如果 P-value ≤ α: 拒绝H₀(结果统计显著)
- 如果 P-value > α: 不拒绝H₀(结果不显著)
常见显著性水平
- α = 0.05: 最常用,5%的错误率
- α = 0.01: 更严格,1%的错误率
- α = 0.10: 较宽松,10%的错误率
Types of Errors (错误类型)
Type I Error (第一类错误, α错误)
- 定义: 拒绝了真实的H₀(假阳性)
- 概率:
- 例子: 认为药物有效,实际无效
Type II Error (第二类错误, β错误)
- 定义: 未能拒绝错误的H₀(假阴性)
- 概率:
- 例子: 认为药物无效,实际有效
Power (检验功效)
- 定义: 正确拒绝错误H₀的概率
- 公式: Power =
- 影响因素:
- 样本量n(n越大,power越高)
- 效应大小(效应越大,power越高)
- 显著性水平α(α越大,power越高,但Type I error也增加)
权衡
- 降低α会增加β(降低Type I error会增加Type II error)
- 增加样本量可以同时降低两种错误
One-sample Z-test for Proportions (单样本比例Z检验)
假设
- 随机样本: 数据来自随机样本
- 独立性: 观测值相互独立
- 样本量: 且 (正态近似条件)
步骤
1. 设定假设
- (或 或 )
2. 计算检验统计量
3. 计算P-value
- 双侧:
- 右侧:
- 左侧:
4. 做出决策
- 比较P-value与α
- 得出结论
R中实现
# 使用prop.test
prop.test(x=60, n=100, p=0.5, alternative="two.sided", correct=FALSE)
# 手工计算
p_hat <- 60/100
p_0 <- 0.5
n <- 100
SE <- sqrt(p_0*(1-p_0)/n)
z_obs <- (p_hat - p_0)/SE
p_value <- 2*pnorm(abs(z_obs), lower.tail=FALSE)例子:完整检验
问题: 一枚硬币抛100次,出现60次正面。这枚硬币是公平的吗?(α=0.05)
解答:
-
假设:
- (硬币公平)
- (硬币不公平)
-
检验统计量:
-
P-value:
- P-value =
-
决策:
- P-value (0.0456) < α (0.05)
- 拒绝H₀
-
结论:
- 在5%显著性水平下,有足够证据表明硬币不公平
Two-sample Z-test for Proportions (双样本比例Z检验)
目的
- 比较两个总体的比例是否相等
假设
- (或 )
- (或其他)
检验统计量
Pooled proportion (合并比例):
标准误:
Z统计量:
R中实现
# 使用prop.test
prop.test(x=c(x1, x2), n=c(n1, n2), correct=FALSE)
# 或者
prop.test(table(group, outcome))例子
问题:
- 组1: 100人中60人成功
- 组2: 120人中50人成功
- 两组成功率是否不同?
解答:
prop.test(x=c(60, 50), n=c(100, 120), correct=FALSE)Continuity Correction (连续性修正)
为什么需要?
- 比例是离散的,但正态分布是连续的(-Proportions are discrete, but the normal distribution is continuous)
- 连续性修正提高小样本的准确性(- Continuity correction improves the accuracy of small samples)
Yates' Continuity Correction
- R中
prop.test()默认使用 - 对于大样本,影响很小
- 使用
correct=FALSE关闭
何时使用
- 小样本: 使用修正(
correct=TRUE) - 大样本: 可以不用(
correct=FALSE) - 与手工计算比较: 使用
correct=FALSE
Topic 10: Tests for Mean (均值检验)
One-sample Z-test for Mean (单样本均值Z检验)
何时使用
- 检验总体均值是否等于某个特定值
- 已知总体标准差σ
假设
- 随机样本
- 独立性
- 正态性: 总体正态分布,或样本量足够大(n≥30,CLT)
假设设定
- (或 或 )
检验统计量
其中:
- : 样本均值
- : 原假设中的均值
- : 总体标准差(已知)
- : 样本量
P-value计算
# 双侧
p_value <- 2 * pnorm(abs(z_obs), lower.tail=FALSE)
# 右侧
p_value <- pnorm(z_obs, lower.tail=FALSE)
# 左侧
p_value <- pnorm(z_obs)例子
问题: 某品牌声称其产品平均重量为500g,σ=10g。抽取36个产品,平均重量495g。检验声称是否正确(α=0.05)。
解答:
- ,
- P-value =
- P-value < 0.05,拒绝H₀
- 结论: 有证据表明平均重量不是500g
One-sample T-test for Mean (单样本均值T检验)
何时使用
- 检验总体均值
- 未知总体标准差σ(最常见情况)
与Z-test的区别
- 使用样本标准差s估计σ
- 使用t分布而非正态分布
- t分布有更厚的尾部(考虑了估计σ的不确定性)
检验统计量
其中:
- : 样本标准差
- 自由度:
假设
- 随机样本
- 独立性
- 正态性:
- 总体正态分布(小样本必需)
- 或样本量足够大(n≥30)
- 或数据近似对称,无极端异常值
R中实现
# 单样本t检验
t.test(data, mu=mu_0, alternative="two.sided")
# alternative选项:
# "two.sided" - 双侧检验
# "greater" - 右侧检验 (H₁: μ > μ₀)
# "less" - 左侧检验 (H₁: μ < μ₀)例子
# 数据
weights <- c(495, 502, 488, 510, 493, 505)
# 检验 H₀: μ = 500
t.test(weights, mu=500)
# 输出包括:
# - t统计量
# - 自由度
# - P-value
# - 95%置信区间
# - 样本均值Two-sample T-test (双样本T检验)
目的
- 比较两个独立总体的均值是否相等
假设
- (或 )
- (或其他)
假设条件
- 两个独立随机样本
- 正态性: 两个总体都正态分布(或样本量足够大)
- 方差齐性: (对于标准t检验)
检验统计量(等方差假设)
Pooled standard deviation (合并标准差):
标准误:
t统计量:
自由度:
R中实现
# 等方差假设(默认不使用)
t.test(group1, group2, var.equal=TRUE)
# 不等方差(Welch t-test,默认)
t.test(group1, group2, var.equal=FALSE)
# 或使用公式语法
t.test(value ~ group, data=mydata)Welch T-test (Welch检验)
何时使用:
- 两组方差不相等时
- R中
t.test()的默认方法
特点:
- 不假设方差齐性
- 使用修正的自由度(通常不是整数)
- 更稳健,推荐使用
检验统计量:
自由度 (Welch-Satterthwaite公式):
例子
# 两组数据
group_A <- c(23, 25, 27, 29, 31)
group_B <- c(30, 32, 35, 37, 40)
# Welch t-test (推荐)
t.test(group_A, group_B)
# 标准t-test (等方差)
t.test(group_A, group_B, var.equal=TRUE)Paired T-test (配对T检验)
何时使用
- 两个样本不独立
- 配对或匹配的观测
- 同一对象的前后测量
例子
- 治疗前后的测量
- 同一个体的左右手
- 配对的双胞胎
- 同一地点不同时间的测量
原理
- 计算每对观测的差值
- 对差值进行单样本t检验
假设
- (差值的均值为0)
检验统计量
其中:
- : 差值的均值
- : 差值的标准差
- : 配对数
R中实现
# 方法1: 两个向量
t.test(before, after, paired=TRUE)
# 方法2: 手工计算差值
differences <- after - before
t.test(differences, mu=0)
# 两种方法等价例子
问题: 10名学生参加培训前后的考试成绩,培训是否有效?
before <- c(65, 70, 68, 72, 75, 69, 71, 73, 67, 74)
after <- c(70, 75, 72, 78, 80, 73, 76, 77, 71, 79)
# 配对t检验
t.test(before, after, paired=TRUE)
# 或者
diff <- after - before
t.test(diff, mu=0, alternative="greater") # 单侧检验Paired vs Two-sample T-test
| 特征 | Paired T-test | Two-sample T-test |
|---|---|---|
| 数据结构 | 配对数据 | 独立样本 |
| 样本量 | 可以不同大小但必须配对 | 可以不同大小 |
| 检验对象 | 差值的均值 | 两组均值的差 |
| 功效 | 通常更高(控制个体差异) | 较低 |
| 假设 | 差值正态分布 | 两组各自正态分布 |
重要: 错误地使用two-sample t-test分析配对数据会损失统计功效
Assumptions and Diagnostics (假设与诊断)
正态性检验
1. 图形方法
Histogram (直方图):
hist(data)- 查看是否近似钟形
Q-Q Plot (分位数-分位数图):
qqnorm(data)
qqline(data)- 点应该大致在直线上
- 最常用的诊断工具
Boxplot (箱线图):
boxplot(data)- 查看对称性和异常值
2. 统计检验
Shapiro-Wilk Test:
shapiro.test(data)- : 数据来自正态分布
- P-value > 0.05: 不拒绝正态性
- 注意: 对大样本非常敏感,小偏离也会显著
Kolmogorov-Smirnov Test:
ks.test(data, "pnorm", mean=mean(data), sd=sd(data))方差齐性检验
Levene's Test:
library(car)
leveneTest(value ~ group, data=mydata)- : 方差相等
- P-value > 0.05: 方差齐性
F-test:
var.test(group1, group2)- 对正态性假设敏感
- 不如Levene's test稳健
违反假设时的处理
1. 非正态性
- 小样本: 考虑非参数检验
- 大样本: CLT保证t检验稳健
- 严重偏态: 数据转换(log, sqrt)
- 异常值: 检查数据质量,考虑删除或使用稳健方法
2. 方差不齐
- 使用Welch t-test (R默认)
- 数据转换
3. 非独立性
- 使用配对t检验
- 混合效应模型
- 时间序列方法
Non-parametric Tests (非参数检验)
何时使用
- 数据严重偏态
- 存在极端异常值
- 样本量很小且不满足正态性
- 顺序数据(ordinal data)
Wilcoxon Signed-Rank Test (Wilcoxon符号秩检验)
用途: 单样本或配对样本的非参数替代
假设:
- : 中位数 = (或配对差值的中位数=0)
R中实现:
# 单样本
wilcox.test(data, mu=m_0)
# 配对样本
wilcox.test(before, after, paired=TRUE)原理:
- 计算差值(或与的差)
- 对差值的绝对值排秩
- 根据差值的符号分配秩的符号
- 计算正秩和或负秩和
Mann-Whitney U Test (Mann-Whitney U检验)
也称: Wilcoxon Rank-Sum Test
用途: 双样本t检验的非参数替代
假设:
- : 两组的分布相同(或中位数相等)
R中实现:
wilcox.test(group1, group2)
# 或
wilcox.test(value ~ group, data=mydata)原理:
- 合并两组数据并排秩
- 计算每组的秩和
- 检验秩和是否显著不同
非参数检验的特点
优点:
- 不需要正态性假设
- 对异常值稳健
- 适用于顺序数据
缺点:
- 功效通常低于参数检验(当假设满足时)
- 检验的是分布或中位数,不是均值
- 解释不如参数检验直观
参数 vs 非参数检验对比
| 情况 | 参数检验 | 非参数检验 |
|---|---|---|
| 单样本 | One-sample t-test | Wilcoxon signed-rank |
| 配对样本 | Paired t-test | Wilcoxon signed-rank |
| 两独立样本 | Two-sample t-test | Mann-Whitney U |
| 多组比较 | ANOVA | Kruskal-Wallis |
Effect Size (效应量)
为什么需要?
- P-value只告诉我们效应是否存在
- 不告诉我们效应有多大
- 大样本下,微小的效应也可能显著
Cohen's d
定义: 标准化的均值差
单样本或配对:
两独立样本:
解释:
- |d| = 0.2: 小效应
- |d| = 0.5: 中等效应
- |d| = 0.8: 大效应
R中计算:
library(effsize)
cohen.d(group1, group2)置信区间 vs P-value
置信区间的优势:
- 提供效应量的估计
- 显示估计的精度
- 更有信息量
建议: 报告置信区间和P-value
Topic 11: Tests for Relationship (关系检验)
Chi-square Test (卡方检验)[[Chi-square Test]]
概述
- 用于分类变量(categorical variables)
- 检验观察频数与期望频数的差异
- 三种主要类型
Chi-square Distribution (卡方分布)
性质:
- 右偏分布
- 只有正值
- 由自由度(df)决定形状
- 记号:
自由度越大,分布越接近正态
1. Chi-square Goodness of Fit Test (拟合优度检验)
目的
- 检验观察到的频数分布是否符合理论分布
假设
- : 数据符合指定的分布
- : 数据不符合指定的分布
检验统计量
其中:
- : 观察频数(Observed)
- : 期望频数(Expected)
- : 类别数
期望频数计算
- : 总样本量
- : 第i类的理论概率
假设条件
- 独立性: 观测独立
- 样本量: 每个类别的期望频数 ≥ 5
R中实现
# 观察频数
observed <- c(25, 30, 20, 25)
# 期望概率(如果相等)
expected_prob <- c(0.25, 0.25, 0.25, 0.25)
# 卡方检验
chisq.test(observed, p=expected_prob)例子
问题: 一个骰子投掷120次,各面出现次数如下。骰子是否公平?
| 面 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 观察 | 15 | 18 | 22 | 20 | 24 | 21 |
解答:
observed <- c(15, 18, 22, 20, 24, 21)
expected_prob <- rep(1/6, 6) # 每面概率1/6
chisq.test(observed, p=expected_prob)
# 期望频数: 120 * 1/6 = 20 (每面)
# df = 6 - 1 = 52. Chi-square Test for Homogeneity (齐性检验)
目的
- 检验两个或多个总体的分布是否相同
- 比较不同组在分类变量上的分布
假设
- : 各组的分布相同
- : 至少有一组的分布不同
数据结构
- 列联表 (Contingency table): 行代表组,列代表类别
检验统计量
期望频数:
自由度:
- : 行数
- : 列数
R中实现
# 创建列联表
table_data <- matrix(c(30, 20, 10,
25, 25, 20),
nrow=2, byrow=TRUE)
rownames(table_data) <- c("Group A", "Group B")
colnames(table_data) <- c("Cat1", "Cat2", "Cat3")
# 卡方检验
chisq.test(table_data)
# 或从原始数据
chisq.test(table(group, category))例子
问题: 两个班级学生对课程的满意度是否不同?
| 满意 | 中立 | 不满意 | |
|---|---|---|---|
| 班级A | 40 | 30 | 10 |
| 班级B | 30 | 35 | 15 |
解答:
data <- matrix(c(40, 30, 10,
30, 35, 15), nrow=2, byrow=TRUE)
result <- chisq.test(data)
result
# 查看期望频数
result$expected
# df = (2-1)(3-1) = 23. Chi-square Test for Independence (独立性检验)
目的
- 检验两个分类变量是否独立
- 与齐性检验公式相同,但解释不同
假设
- : 两个变量独立
- : 两个变量不独立(有关联)
区别:齐性 vs 独立性
| 特征 | 齐性检验 | 独立性检验 |
|---|---|---|
| 研究问题 | 不同组的分布是否相同 | 两个变量是否独立 |
| 抽样方式 | 固定行(或列)边际 | 只固定总样本量 |
| 例子 | 比较男女的投票偏好 | 研究吸烟与肺癌的关系 |
数学上: 两者使用相同的检验统计量和自由度
R中实现
# 与齐性检验相同
chisq.test(table(variable1, variable2))例子
问题: 性别与是否喜欢数学是否独立?
| 喜欢 | 不喜欢 | |
|---|---|---|
| 男 | 60 | 40 |
| 女 | 40 | 60 |
解答:
data <- matrix(c(60, 40,
40, 60), nrow=2, byrow=TRUE)
chisq.test(data)
# 如果P-value < 0.05,拒绝独立性
# 结论:性别与喜欢数学有关联Chi-square Test的假设和限制
假设
- 独立性: 观测必须独立
- 期望频数:
- 所有单元格的期望频数 ≥ 1
- 至少80%的单元格期望频数 ≥ 5
违反假设时的处理
期望频数过小:
- 合并类别: 将频数小的类别合并
- Fisher's Exact Test: 用于2×2表格
fisher.test(table_data) - 增加样本量
Fisher's Exact Test (Fisher精确检验)
何时使用:
- 2×2列联表
- 期望频数 < 5
- 小样本
R中实现:
fisher.test(table_data)优点: 精确的P-value,不依赖近似 缺点: 计算密集,大样本时不实用
Effect Size for Chi-square (卡方检验的效应量)
Cramér's V
公式:
范围: 0 到 1
解释 (对于df=1):
- V = 0.1: 小效应
- V = 0.3: 中等效应
- V = 0.5: 大效应
R中计算:
library(lsr)
cramersV(table_data)Phi Coefficient (φ系数)
用于: 2×2表格
公式:
等价于: Cramér's V (当df=1时)
T-test for Regression Slope (回归斜率的T检验)
目的
- 检验回归线的斜率是否显著不为0
- 判断x和y之间是否存在线性关系
假设
- (斜率为0,无线性关系)
- (斜率不为0,存在线性关系)
检验统计量
其中:
- : 样本回归斜率
- : 斜率的标准误
标准误:
自由度:
R中实现
# 拟合线性模型
model <- lm(y ~ x)
# 查看摘要(包含t检验)
summary(model)
# 输出包括:
# - Estimate: 斜率估计
# - Std. Error: 标准误
# - t value: t统计量
# - Pr(>|t|): P-value解释输出
# 示例输出
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.5000 0.5000 5.000 0.00012 ***
x 1.2000 0.1500 8.000 1.2e-07 ***解释:
- 斜率 = 1.2
- SE = 0.15
- t = 8.0
- P-value < 0.001
- 结论: 斜率显著不为0,x和y有显著线性关系
与相关系数的关系
检验斜率 = 0 等价于 检验相关系数 = 0
# 方法1: 回归
summary(lm(y ~ x))
# 方法2: 相关检验
cor.test(x, y)
# 两者P-value相同假设
- 线性关系: x和y之间是线性的
- 独立性: 观测独立
- 正态性: 残差正态分布
- 同方差性: 残差方差恒定
- 无异常值: 没有极端影响点
诊断
残差图:
model <- lm(y ~ x)
plot(model)
# 4个诊断图:
# 1. Residuals vs Fitted: 检查线性和同方差性
# 2. Q-Q plot: 检查正态性
# 3. Scale-Location: 检查同方差性
# 4. Residuals vs Leverage: 检查影响点置信区间
斜率的置信区间:
confint(model)
# 或手工计算
b <- coef(model)[2]
se_b <- summary(model)$coefficients[2, 2]
t_crit <- qt(0.975, df=n-2)
CI <- b + c(-1, 1) * t_crit * se_bMultiple Testing (多重检验)
问题
- 进行多次检验时,Type I error累积
- 如果α=0.05,进行20次检验,期望有1次假阳性
Family-wise Error Rate (FWER)
- : 检验次数
修正方法
1. Bonferroni Correction (Bonferroni修正)
调整显著性水平:
例子: 进行5次检验,α=0.05
- 调整后:
R中实现:
p.adjust(p_values, method="bonferroni")特点:
- 保守(降低功效)
- 简单易用
2. Holm Method (Holm方法)
步骤:
- 将P-values从小到大排序
- 对第i个P-value,比较与
- 拒绝直到第一个不显著的检验
R中实现:
p.adjust(p_values, method="holm")特点: 比Bonferroni功效更高
3. False Discovery Rate (FDR)
Benjamini-Hochberg方法:
- 控制假发现率而非FWER
- 更适合大量检验(如基因组学)
R中实现:
p.adjust(p_values, method="fdr")
# 或
p.adjust(p_values, method="BH")总结:检验选择流程图
数据类型?
├─ 分类变量
│ ├─ 一个变量 → Chi-square Goodness of Fit
│ ├─ 两个变量
│ │ ├─ 独立性 → Chi-square Independence
│ │ └─ 比较组 → Chi-square Homogeneity
│ └─ 2×2表格,小样本 → Fisher's Exact Test
│
└─ 连续变量
├─ 一个样本
│ ├─ σ已知 → Z-test
│ ├─ σ未知,正态 → One-sample t-test
│ └─ 非正态 → Wilcoxon signed-rank
│
├─ 两个样本
│ ├─ 独立
│ │ ├─ 正态,等方差 → Two-sample t-test
│ │ ├─ 正态,不等方差 → Welch t-test
│ │ └─ 非正态 → Mann-Whitney U
│ │
│ └─ 配对
│ ├─ 正态 → Paired t-test
│ └─ 非正态 → Wilcoxon signed-rank
│
└─ 关系
├─ 线性关系 → T-test for regression slope
└─ 相关性 → Correlation test (cor.test)最后更新 · 2026-05-19 23:52